Introduction
Having watched and read a couple of resources for this post, I think the best way to motivate a discussion about pair programming and its benefits is this quote by Dave Farley of the Continuous Delivery channel on YouTube:
“I often describe software development as an exercise in learning. […] science is humanities best approach to learning […]. But there is another aspect to being great at learning. And that’s other people.” — Dave Farley, You Must Be CRAZY To Do Pair Programming
I think this is very true for at least two reasons:
- working as a programmer means continuous learning and
- learning from someone else is usually more efficient than self-learning.
In fact, a good deal of the practical lessons I learned about software engineering, I learned from other developers. Among other things,
- to prefer simple and easily feasible solutions over “smart” ones (i.e. upholding the KISS and YAGNI principles),
- being clever about design decisions (e.g. withstanding the urge to pick the new, cool technology without careful deliberation), and
- a whole lot of useful techniques, tools and gadgets for improving my workflow and work ergonomics.

Pair programming is a mode of working in software development whereby two programmers collaborate on a single task. In classic pair programming, there is a particular mode of working together. Instead of splitting the workload and working in parallel, both programmers take on dedicated roles: one of the developers called the driver takes the proverbial “driver’s seat” and actually writes the code, whereas the other programmer called the navigator acts as a “co-pilot” gives direct feedback to the driver and thinks ahead about what to do next. Albeit very simple concept wise, pair programming has a lot of positive effects in my experience. Not only is it a natural knowledge distribution channel, but it also seems to result in better code with less time spent on reviews and subsequent changes.
Pros and cons of pair programming
Granted, this is just my anecdotal experience. Personally, I enjoy pair programming and think it should be the default mode of working together on porgramming tasks for the reasons stated above. To be fair though, my short look through the literature didn’t generally support all positive aspects. There however seems to be a consensus that pair programming is most well suited for complex programming tasks that involve a lot of learning and which require upholding a high quality standard. For standardized and simple tasks it might not necessarily efficient to apply pair programming.
Williams (5) is an example for a paper that paints a very positive picture. They report pair programming has shown to improve
- quality (less defects),
- knowledge sharing,
- readability,
- team morale, and in some cases even
- cost effectiveness and productivity.
For industrial settings.
Improvements in cost effectiveness and productivity might be a bit surprising since it seems counterintuitive that two programmers doing the same task will produce more work than two programmers working independently. Particularly, if one of them is not writing any code. Also, even if a pair of programmers had doubled productivity—which is not always realistic—, they would also incur double the cost. This would of course mean that even under generous assumptions there is no improvement in cost effectiveness to be expected. Moreover, using a direct—and arguably naive—measure of productivity such as lines of code (LoC), we might actually observe the oppositve effect. Pair programming will likely result in more compact code and therefore less productivity in terms of LoC.
The cost effectiveness of pair programming unfortunately is indirect and therefore not directly apparent. To appreciate it, we need to have some insight into the software production process and its challenges. Primarily that defects typically produce more cost the later they are detected. So, the motivation of reducing money spent on fixing bugs should drive project managers to adopt measures to improve quality early on. Generally, as Padberg & Müller (6) note, the main factors to consider in a cost-benefit analyis of pair programming therefore are the
- doubled personnel cost and the
- cost reduction via productivity increase and reduced bug-fixing cost.
Consequently, we should in general see positive effects of pair programming on cost efffectiveness when the combination of productivity increase and reduced bug fixing costs compensate the double personnel cost.
Per Abrahamsson & Hulkko (7), there however seems not to be clear, empirical evidence that productivity increase and reduced bug fixing costs will generally be observed in software development projects that apply pair programming. That being said, their empirical evidence supports that pair programming is best suited for complex and learning tasks and produces more readable code.
My assumption would be that in general both productivity increase and reduced bug fixing cost are linked to the scale of the project. In my short literature review, I did not find an empirical study which supports or refutes this, however. It may or may not be true for any concrete project and should be evaluated. Since pair programming may also improve team morale however, another important driving factor may be reducing the risk of key developers leaving the project (which should obviously not be underestimated).
Pair programming in agile projects

Another important thing to consider is the impact of time-to-market on the project success. Typically, a faster time-to-market for features is beneficial to any project due to for example customer expectations on quality and delivery speed. In software projects, faster development cycles are also highly valuable because integration of changes is easier if the code base does not deviate too much inbetween starting and finishing a feature. Project managers will therefore likely push to deliver features as soon as possible.
A good overview on the value of fast time-to-market is given in (8).
Now, does this speak for or against pair programming? I think it speaks for pair programming. Since under the assumption that two programmers will work nearly twice as fast as two individual programmers, we should see faster delivery of features with pair programming compared to parallel feature development. This is somewhat supported by queuing theory as well—specifically Little’s law—which tells us that in the long term a constant relationship
exists between the amount of work in progress at any given point, the rate at which new work comes in and the processing time of each unit of work. Even more surprisingly, this is independent of the distribution of incoming work. We can therefore—at least in theory—equivalently switch to less work done in parallel (lower ) if we can compensate through higher productivity (higher ).
Example
Lets have a look at a very small project team consisting of two developers. We target story points per sprint with new stories per sprint (one for each developer). For simplicity’s sake, we will assume that each story has exactly 10 story points and will be finished by their assigned developer exactly at the end of the sprint. Every one of our two developers therefore has to have a processing capacity of story points per sprint.
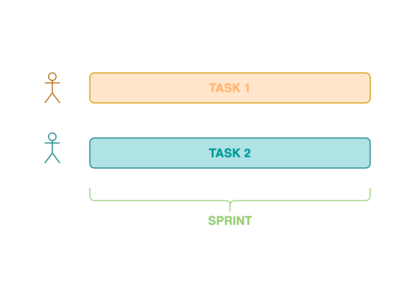
Now, let’s split up the work and do both stories in pairs. We assume that our programmer pair has double the capacity of the single programmers . Since we now only work on one story at the same time, we have to halve the amount of new incoming stories to . The amount of work done will stay the same regardless, since
However this time, since every story has 10 story points and two developers finish 20 story points per sprint, the programmer pair finishes their story in half a sprint and then starts working on the remaining other story. In essence, by doing pair programming, we gain the capability to release one feature per sprint earlier than when everything is done in parallel.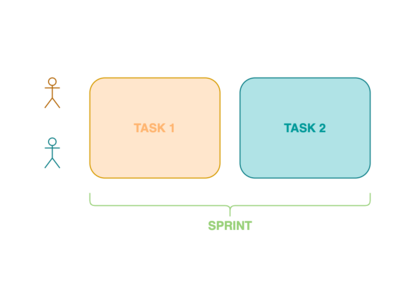


This might not seem like a profound insight, but in combination with the benefits of faster time-to-market, we should gain a net positive for the project by switching to pair programming (given that is close to ) even if no other improvement is being observed.
Remote pairing with mob.sh
Traditionally, when it was popularized by the Extreme Programming agile framework, pair programming not only meant working on a single task but also at a shared work place (in fact a single computer and one set of mouse and keyboard).
Recently—accelerated massively by the corona pandemic—, remote collaboration has become more and more popular (even necessary). It therefore makes sense to include remote collaboration setups into the pair programming concept. Typically, this entails some kind of video conferencing and screen sharing solution (such as Slack, Microsoft Teams or Zoom) as well as remote code repositories. In the remote setting, the remote pair programming duo will typically open a remote meeting room for themselves where the driver shares his screen to the navigator.
Starting and finishing a remote pairing session as well as handovers typically coincide with push to and pull from a remote repository. This comes with it’s own pitfalls and may introduce negative effects on productivity. So, automation is our friend. One of the tools which help in this respect is mob.sh. We’ll take a look at how to install and use it in the this section.
Installation
On macOS we can use Brew
brew install remotemobprogramming/brew/mobFor other platforms, check the Mob.sh home page.
Basic pair programming workflow with mob.sh
We assume a simple, branch-based Git workflow model like GitHub flow. The feature we are working on will therefore be developed on some feature branch feat/X. So, first we check out a feature branch and push it to the remote.
$ git checkout -b feat/X
Switched to a new branch 'feat/X'
$ git push -u origin HEAD
Total 0 (delta 0), reused 0 (delta 0), pack-reused 0
remote:
remote: Create a pull request for 'feat/X' on GitHub by visiting:
remote: https://github.com/fkurz/mob-test/pull/new/feat/X
remote:
To github.com:fkurz/mob-test.git
* [new branch] HEAD -> feat/X
Branch 'feat/X' set up to track remote branch 'feat/X' from 'origin'.The remote branch is necessary to hand over changes if we are not using the same computer. Now, we start the pair programming session with mob.sh by running mob start
$ mob start
git fetch origin --prune
git merge FETCH_HEAD --ff-only
> starting new session from origin/feat/X
git checkout -B mob/feat/X origin/feat/X
git push --no-verify --set-upstream origin mob/feat/X
> you are on wip branch 'mob/feat/X' (base branch 'feat/X')
> It's now 09:48. Happy collaborating!As we can see, the start command first pulls—i.e. fetches and then merges—the remote state of the feature branch. Then, it creates the mob branch mob/feat/X if it doesn’t exist yet, resets it and switches to it from the feature branch (using git checkout-B ). Lastly, the mob branch is pushed to the remote.
--include-uncommitted-changesoption.
Now, the driver who started the session will simply push their changes to the mob branch. Once we are ready for a handover, the driver will run mob next and by doing so commits all changes and pushes them to the remote.
$ echo "mob.sh is awesome" > mob.txt
$ mob next
git add --all
git commit --message mob next [ci-skip] [ci skip] [skip ci] --no-verify
mob.txt | 1 +
1 file changed, 1 insertion(+)
8e6926e4839e7710d97240d05fa08c739d007af2
git push --no-verify origin mob/feat/X
$ git --no-pager log origin/mob/feat/X
commit 8e6926e4839e7710d97240d05fa08c739d007af2 (HEAD -> mob/feat/X, origin/mob/feat/X)
Author: Friedrich Kurz <friedrich.kurz@live.com>
Date: Sat Jan 15 09:50:22 2022 +0100
mob next [ci-skip] [ci skip] [skip ci]
commit e27ef3e207de0a8722508a9a17bc6f9b217e4ea0 (origin/main, origin/feat/X, origin/HEAD, main, feat/X)
Author: Friedrich Kurz <40720053+fkurz@users.noreply.github.com>
Date: Sat Jan 15 09:45:44 2022 +0100
Initial commitOne nice thing to note is that mob.sh uses the --no-verify option for git commit. This will disable pre-commit checks which might disrupt the handover process if there are temporary changes which do not pass validation. (These should of course be dealt with eventually.)
-mor--messageoptions tomob next. E.g.mob next -m 'Add some tests'will add the commit message “Add some tests” to the handover commit.
The new driver can now simply run mob start from the feature branch feat/X in order to pull the changes from the remote mob branch and continue working. We can simulate this locally by first deleting the mob branch mob/feat/X.
$ git branch -D mob/feat/X
Deleted branch mob/feat/X (was 8e6926e).
$ git --no-pager branch -a
* feat/X
main
remotes/origin/HEAD -> origin/main
remotes/origin/feat/X
remotes/origin/main
remotes/origin/mob/feat/X
$ mob start
git fetch origin --prune
git merge FETCH_HEAD --ff-only
> joining existing session from origin/mob/feat/X
git checkout -B mob/feat/X origin/mob/feat/X
git branch --set-upstream-to=origin/mob/feat/X mob/feat/X
> you are on wip branch 'mob/feat/X' (base branch 'feat/X')
8e6926e 3 minutes ago <Friedrich Kurz>
> It\'s now 09:53. Happy collaborating!
$ git --no-pager branch
feat/X
main
* mob/feat/X
$ git --no-pager log
commit 8e6926e4839e7710d97240d05fa08c739d007af2 (HEAD -> mob/feat/X, origin/mob/feat/X)
Author: Friedrich Kurz <friedrich.kurz@live.com>
Date: Sat Jan 15 09:50:22 2022 +0100
mob next [ci-skip] [ci skip] [skip ci]
commit e27ef3e207de0a8722508a9a17bc6f9b217e4ea0 (origin/main, origin/feat/X, origin/HEAD, main, feat/X)
Author: Friedrich Kurz <40720053+fkurz@users.noreply.github.com>
Date: Sat Jan 15 09:45:44 2022 +0100
Initial commitThe commit history of a feature with two mob sessions would look something like this
flowchart
subgraph main
M1((M1)) --- M2((M2))
M2 --- M3((M3))
%% feat/X
M2 --- X1((X1))
subgraph feat/X
%% first mob session
subgraph "mob/feat/X (first session)"
X1 --- X2((...))
X2 --- Xk((X_k))
end
Xk --- Xkplus1((Xk+1))
Xkplus1 --- Xkplus2((Xk+2))
%% second mob session
subgraph "mob/feat/X (second session)"
Xkplus2 --- Xkplus3((...))
Xkplus3 --- Xkplusl((Xk+l))
end
Xkplusl --- Xkpluslplus1((Xk+l+1))
end
Xkpluslplus1 --- M3
M3 --- M4((M4))
end
Once we’re done with the pairing session, we run mob done which will again add and commit all changes. However, in contrast to mob next, mob.sh will switch to the feature branch feat/X, merge the changes of the mob branch and delete it.
$ echo "\nyes, it's awesome" >> mob.txt
$ mob done
git fetch origin --prune
git add --all
git commit --message mob next [ci-skip] [ci skip] [skip ci] --no-verify
mob.txt | 2 ++
1 file changed, 2 insertions(+)
66d688516e03869be5bfc3e4cabb04c79c0d49ad
git push --no-verify origin mob/feat/X
git checkout feat/X
git merge origin/feat/X --ff-only
git merge --squash --ff mob/feat/X
git branch -D mob/feat/X
git push --no-verify origin --delete mob/feat/X
mob.txt | 3 +++
1 file changed, 3 insertions(+)
👉 To finish, use
git commitTo conclude the pairing workflow we simply run git commit to commit the changes from our mob branch to the feature branch and then git push to push them to the remote repository.
More information on mob.sh after the jump

Sources
General
- Dave Farley — You Must Be CRAZY To Do Pair Programming
- Martin Fowler — On Pair Programming
- mob.sh homepage
- How to apply Little’s Law to ensure successful project completion
- Neil McKinnon — Time-To-Market (TTM)